事件循环
主要负责管理任务队列,使得 JavaScript 代码能够正常地执行异步任务
事件循环可以说是 JavaScript 实现异步编程最核心的部分
进程
程序运行时它自己专属的内存空间,每个程序启动时至少有一个进程
线程
进程中的一个执行单元,一个进程中至少有一个线程,在进程开启后会自动创建一个线程来运行代码,该线程称为主线程
类比:运行代码的"人"称为线程,进程就是"公司"
浏览器有哪些进程和线程
浏览器是一个多进程多线程的应用程序,因为它的内部工作极为复杂,为了避免相互影响减少连环崩溃的几率,当启动浏览器之后它会自动启动多个进程
主要的进程有三个:浏览器进程、网络进程、渲染进程
- 浏览器进程 主要负责界面显示、用户交互、子进程管理、存储等
- 网络进程 主要负责页面的网络资源加载
- 渲染进程 渲染进程启动后,会开启一个渲染主进程,负责执行HTML、CSS、JS代码
默认情况下浏览器会为每个标签页开启一个新的渲染进程,保证各个标签页互不影响
它处理的任务包括但不仅限于:- 解析HTML
- 解析CSS
- 计算样式
- 布局
- 处理图层
- 每秒把页面画60次(FPS)
- 执行全局JS代码
- 执行事件处理函数
- 执行计时器的回调函数
- ......
TIP
思考:为什么渲染进程不使用多个线程来处理这些事情?
消息队列
- 最开始的时候,渲染主线程会进入一个无限循环
- 每一次循环都会检查消息队列中是否有任务,如果有则取出一个任务,然后执行该任务,执行完一个后进入下一次循环,如果没有则进入休眠状态
- 其他所有线程(包括其他进程的线程)可以随时往消息队列添加任务,新任务会添加到末尾,在添加时如果主线程是休眠状态,则会将其唤醒继续循环拿取任务
宏任务
- 例如
- setTimeout 、setInterval和 setImmediate 定时器任务
- 网络请求和 I/O 相关任务
- UI 渲染相关任务
- 响应用户交互事件的任务
- 执行顺序
- 首先,宏任务队列中所有的"立即执行函数"会被执行
- 接着,按照它们被添加到队列中的顺序逐一执行
- 执行过程中如果有新的宏任务,则会添加到队列末尾
微任务
- 例如
- Promise 的 then/catch/finally 方法
- MutationObserver 监听器
H5 新增的 DOM API,可监听 DOM 节点的变化,并在变化后执行回调函数 - queueMicrotask 函数
ES2020 新增的 API,用于将回调函数添加到微任务队列中,类似 Promise 的 then 方法,只是没有 Promise 对象的创建和返回,因此相比 Promise.then 更为轻量
轻量的同时,它没有 Promise 那样完整的异步 API,例如 catch() finally() 方法等,也没有链式调用
也可能会与 MutationObserver 竞争,因为它们都是使用了微任务队列,但是 MutationObserver 的优先级更高,因此 queueMicrotask 函数的回调函数可能会被延迟执行,因此不太适合在高可靠性的场景中使用
- 执行顺序
- 优先按照添加顺序执行 Promise.then 和 MutationObserver 微任务
- 然后再按照添加顺序执行 queueMicrotask 微任务
TIP
promise.then 和 MutationObserver的优先级都比 queueMicrotask 高
原型链
作用
- 提供属性和方法的继承:通过原型链,子类可以继承父类中的属性和方法,可以大大减少重复代码
- 减少内存使用:由于所有的实例对象共享原型对象,因此可以减少内存的使用,提高程序的性能。
- 构建对象:使用原型链,可以通过构造函数来创建对象,且所有的构造函数都有一个prototype属性,通过该属性可以访问对象的原型。
- 方便修改原型:使用原型链可以方便地修改原型对象,将一些公共的方法和属性添加到原型中,可以让所有的实例对象都能够共享这些方法和属性。
- 动态修改类行为:通过修改原型对象,可以动态地改变类的行为,例如添加新的方法或重写原有方法等。
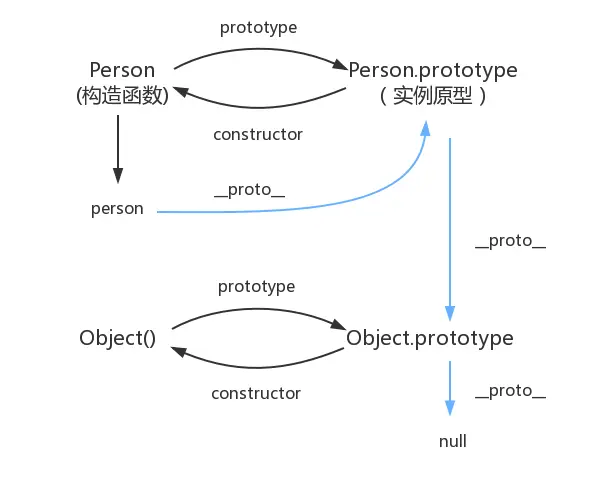
什么是原型链
TIP
- prototype是函数的属性,这个属性的值是一个对象,那么这个对象也有__proto__属性
- __proto__是对象的属性,构造函数实例化出来的对象通过__proto__属性可以访问到构造函数的prototype属性
- 构造函数的prototype的__proto__默认指向Object.prototype,Object.prototype.__proto__指向null;可手动修改__proto__属性,让它指向另外一个构造函数的prototype属性,这样就可以实现原型链的继承
- 不使用原型链的情况:
Person是构造函数,p1和p2是它的实例对象,它们各自的内存空间中都会包含name、age、sex等属性,这样就会造成内存的浪费
function Person(name) {
this.name = name
this.age = 18
this.sex = '男'
}
let p1 = new Person('张三')
let p2 = new Person('李四')
- 使用原型链的情况:
现在p1和p2的内存空间中只包含name属性,age和sex都存在于原型对象中,因此所有的实例对象都可以共享这些属性,这样可减少内存开销
function Person(name) {
this.name = name
}
Person.prototype.age = 18
Person.prototype.sex = '男'
let p1 = new Person('张三')
let p2 = new Person('李四')
- 查找属性的顺序:
先在实例对象中查找,如果没有找到,就会去原型对象中查找,如果还没有找到,就会去原型对象的原型对象中查找,一直找到Object.prototype,如果还没有找到,就会返回undefined
this
- 普通函数
普通函数中的this指向window,严格模式下指向undefined
function fn() {
console.log(this)
}
fn() // window
- 对象方法
对象方法中的this指向调用该方法的对象
let obj = {
name: '张三',
fn: function() {
console.log(this)
}
}
obj.fn() // obj
- 构造函数
构造函数中的this指向实例对象
let _this;
function fn() {
_this = this
}
let obj = new fn()
console.log(_this === obj) // true
- 箭头函数
箭头函数中的this指向定义时所在的对象,而不是调用时所在的对象;
也可以理解为箭头函数没有自己的this,它的this是继承外层代码块的this
let obj = {
a: function() {
return this
},
t: this,
b: () => {
return this
}
}
console.log(obj.a()) // obj
console.log(obj.t) // window
console.log(obj.b()) // window
function fn() {
this.t = this
this.a = () => this
this.b = function() {
return this
}
}
let obj = new fn()
console.log(obj.t === obj) // true
console.log(obj.b() === obj) // true
console.log(obj.a() === obj) // true
call、apply、bind
TIP
- 无法改变箭头函数this指向
- call和apply都是自执行函数,bind返回的是一个新函数,需要手动执行
- call
fn.call(obj, arg1, arg2, ...) - apply
fn.apply(obj, [arg1, arg2, ...]) - bind
fn.bind(obj, arg1, arg2, ...)()
Promise
- Promise是异步编程的一种解决方案,它可以将异步操作队列化,以同步操作的流程表达出来,避免陷入回调地狱,提高了代码的可读性和可维护性
- Promise对象有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)
- Promise对象的状态改变只有两种可能:从pending变为fulfilled和从pending变为rejected,状态改变后就不会再变,任何时候都可以得到这个结果
- 如果Promise中reject抛出错误但并没有捕获,不会中断整个代码,只会影响当前Promise
- 可以配合async和await更优雅的书写
async\await
TIP
- async/await 是一种基于 Promise 的异步编程解决方案,它可以让我们用同步的方式写异步的代码
- async 函数是 Generator 函数的语法糖,在语法上它是一个异步函数,函数体内可以使用 await 关键字来暂停异步执行过程,并等待一个 Promise 实例 resolve
- async函数返回一个Promise对象,可以使用then方法添加回调函数
- await命令后面是一个Promise对象,返回该对象的结果,如果不是Promise对象,就直接返回对应的值
- await命令只能在async函数中使用,如果用在普通函数中,就会报错
作用域
TIP
使用 var 声明的变量在整个函数作用域有效,而使用 let 或 const 声明的变量只在当前的代码块有效
全局作用域
全局作用域中的变量可以在任何地方访问,但是不推荐这样做,因为全局作用域中的变量会污染全局命名空间,容易造成命名冲突
局部作用域
- 函数作用域
函数作用域中的变量只能在函数内部访问,函数外部无法访问 - 块级作用域
ES6新增了块级作用域,用let和const声明的变量只能在块级作用域也就是当前代码块(例如if、for等)中访问
闭包
有权访问另一个函数作用域中的变量的函数。它会涉及到作用域,全局\局部作用域,局部作用域又涉及到函数作用域和块级作用域,这就是作用域链
- 优点
私有化数据,在私有化数据的基础上保持数据 - 缺点 可能会导致内存泄漏
垃圾回收机制
- 标记清除
当变量进入环境时,就将这个变量标记为“进入环境”,当变量离开环境时,则将其标记为“离开环境”。垃圾回收器在运行的时候会给存储在内存中的所有变量都加上标记,然后去掉环境中的变量以及被环境中的变量引用的变量的标记,而在此之后再被加上标记的变量将被视为准备删除的变量,最后垃圾回收器完成内存清除工作,销毁那些带标记的值并回收他们所占用的内存空间 - 引用计数
引用计数的含义是跟踪记录每个值被引用的次数,当声明了一个变量并将一个引用类型的值赋给该变量时,则这个值的引用次数就是1,如果同一个值又被赋给另一个变量,则该值的引用次数加1,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减1,当这个值的引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。但是这种方法存在循环引用的问题,例如下面的代码js在这个例子中,obj1和obj2相互引用,但是在函数执行完毕后,他们并没有被销毁,因为他们的引用次数永远不会变成0,所以这种方法存在循环引用的问题,会导致内存泄漏function problem() { let obj1 = new Object() let obj2 = new Object() obj1.name = obj2 obj2.name = obj1 } - 新生代老生代
- 新生代
新生代中的对象存活时间较短,所以采用复制算法,将新生代内存空间分为两个等大小的空间,使用空间为From,空闲空间为To,活动对象存储在From空间,标记整理后将活动对象复制到To空间,然后清空From空间,From和To交换空间完成释放 - 老生代
老生代中的对象存活时间较长,所以采用标记整理算法,标记整理后将活动对象存储在内存的一端,然后清空另一端的内存空间,完成释放
- 新生代
应用场景
- 模块化
将一些公共的方法封装在一个函数中,然后通过闭包的方式暴露出去,这样就可以实现模块化 - 缓存
例如斐波那契数列,通过闭包可以实现缓存,避免重复计算 - 防抖和节流
防抖就是在一定时间内,只执行一次,节流就是在一定时间内,只执行一次,但是如果在这个时间内再次触发,则重新计算时间 - 函数柯里化
函数柯里化就是将一个接收多个参数的函数转换成接收一个参数的函数,然后返回一个新的函数,这个新的函数接收剩余的参数,然后返回结果,这样就可以实现函数柯里化 - 高阶函数 接受一个函数作为参数或者返回一个函数的函数就是高阶函数,例如map、filter、reduce等
- vue的computed
computed中的函数会被缓存,只有当依赖的数据发生变化时,才会重新执行函数,然后将结果缓存起来,下次再次访问时,就会直接从缓存中取值,而不会重新执行函数js// 定义一个对象 var obj = { price: 100, qty: 2 }; // 定义computed属性 Object.defineProperty(obj, 'total', { get: function() { return this.price * this.qty; } }); // 输出computed属性 console.log(obj.total); // 200 // 修改属性值,自动重新计算computed属性 obj.price = 200; console.log(obj.total); // 400 - vue的响应式原理
vue中的数据都是通过Object.defineProperty来实现响应式的,当访问数据时,会执行get方法,然后将当前的watcher添加到依赖中,当数据发生变化时,会执行set方法,然后通知依赖中的watcher,从而实现响应式 - react的fiber
react中的fiber是通过链表的方式来实现的,每个fiber节点都有一个child属性,指向第一个子节点,然后通过sibling属性指向下一个兄弟节点,最后通过return属性指向父节点,这样就可以通过链表的方式来实现fiber的遍历 - react的hooks
react中的hooks是通过链表的方式来实现的,每个hooks节点都有一个memoizedState属性,指向第一个子节点,然后通过next属性指向下一个兄弟节点,最后通过return属性指向父节点,这样就可以通过链表的方式来实现hooks的遍历
预解析
TIP
- var、function声明的变量和函数会被提升到当前作用域的顶部,let和const声明的变量不会被提升\
- var声明中的赋值操作不会被提升,函数会整个提升
什么是预解析
指在代码执行之前,JavaScript 引擎会对代码进行第一次遍历,将所有变量的声明(不包括赋值操作)和函数声明提升到作用域的顶部。这个过程称为变量提升和函数提升。
let和const声明的变量不会被提升,但是会被初始化为undefined,只有在声明的位置被赋值后,才会被初始化,初始化之前使用会报错提示未初始化之前不能使用
console.log(a) // undefined
console.log(fn) // function fn() {}
console.log(this) // window
var a = 1
function fn() {}
console.log(a) // 报错提示未初始化之前不能使用
console.log(fn) // undefined
console.log(this) // window
let a = 1
let fn = function() {}
console.log(a) // 报错提示未初始化之前不能使用
console.log(fn) // undefined
console.log(this) // window
const a = 1
const fn = function() {}
console.log(a) // 报错提示未初始化之前不能使用
console.log(fn) // undefined
console.log(this) // window
a = 1
fn = function() {}
变量提升
变量提升是指在js代码执行前,会先对变量和函数进行提升,即变量和函数会被提升到当前作用域的顶部,但是只会提升声明,不会提升赋值
console.log(a) // undefined
var a = 1
console.log(a) // 报错提示未初始化之前不能使用
let a = 1
函数提升
函数提升是指在js代码执行前,会先对函数进行提升,即函数会被提升到当前作用域的顶部,但是只会提升声明,不会提升赋值
console.log(fn) // function fn() {}
function fn() {}
console.log(fn) // undefined
let fn = function() {}
事件捕获\事件冒泡
TIP
- 事件捕获:事件从最外层元素开始,一层一层往下传递,直到目标元素,再从目标元素开始,一层一层往上冒泡
- 事件冒泡:事件从目标元素开始,一层一层往上冒泡,直到最外层元素
- 事件捕获阶段:事件从最外层元素开始,一层一层往下传递,直到目标元素
- 事件目标阶段:事件到达目标元素
- 事件冒泡阶段:事件从目标元素开始,一层一层往上冒泡,直到最外层元素
web worker
Web Worker的主要使用场景是在主线程中执行非常耗时的代码或者大量的计算任务,以避免阻塞了主线程,导致用户体验不佳。常见的场景包括图像处理、音视频编解码、大规模数据处理、高复杂度运算等
至于Vue、React这些前端框架,它们之所以没有内置对Web Worker的支持,一方面是因为Web Worker的API属于HTML5标准中的内容,而Vue、React等框架是跨浏览器的框架,并不能保证它们运行的浏览器支持HTML5标准;另一方面,Web Worker的使用相对比较复杂,需要开发者专门编写Worker文件并处理数据同步,这对于普通的业务场景也许并不必要
TIP
如果同步任务的执行时间大于了settimeout的时间,又要保证settimeout按时执行,可以考虑使用web worker
浏览器地址栏输入地址到页面显示出来经历了什么?
DNS解析:浏览器会根据网站地址中的域名(www.baidu.com)去DNS服务器查询对应的IP地址,将查询到的IP地址缓存2起来,方便下次访问同一网站的时候直接使用缓存的地址。
与服务器建立TCP连接:浏览器会使用HTTP协议与远程的服务器建立TCP连接,三次握手确认连接
发送HTTP请求:TCP连接建立后,浏览器会向服务器发送HTTP请求,请求网站的HTML等资源文件
服务器响应:服务器接收到浏览器的请求后,会将响应的HTML等资源文件发送回浏览器
浏览器渲染页面:浏览器接收到服务器响应后,会开始根据HTML、CSS、JavaScript等文件渲染页面
进行媒体文件加载和执行JavaScript脚本:如果页面中包含媒体文件或JavaScript脚本,浏览器会根据需要进行加载,并在加载完成后执行相关脚本
TIP
建立连接(3次握手)
- 第一次握手:客户端发送一个SYN(同步)包到服务器,请求建立连接
- 第二次握手:服务器返回一个SYN-ACK(同步-确认)包给客户端,确认请求,并要求客户端确认
- 第三次握手:客户端发送一个ACK(确认)包到服务器,确认请求。服务器收到ACK包之后,连接建立完毕
断开连接(4次握手)
- 第一次握手:客户端发送一个FIN(结束)包到服务器,请求断开连接
- 第二次握手:服务器收到FIN包后,返回一个ACK(确认)包给客户端,表示已收到关闭请求
- 第三次握手:服务器发送一个FIN包给客户端,表示服务器不再发送数据
- 第四次握手:客户端收到FIN包后,发送一个ACK包给服务器,确认收到关闭请求
为什么是3次和4次:
建立连接的3次握手,是为了确保客户端和服务器之间建立的连接是可靠的、有效的,并且可以开始发送数据。而断开连接的4次握手,是为了确保客户端和服务器之间的数据都已经发送完成,可以断开连接了。
TIP
渲染过程:
解析HTML代码:浏览器会将HTML代码转换为DOM树(Document Object Model,文档对象模型),也就是将页面上的每一个对象都转换为一个节点对象。
解析CSS代码:浏览器会将CSS代码转换为CSS对象模型(CSS Object Model,简称CSSOM),即将页面上每个元素的样式转换为一个对象。
构建渲染树:浏览器会将DOM树和CSSOM合并,生成一棵渲染树(Render Tree),也就是将页面上的DOM节点和CSS样式合并在一起,生成最终的页面布局。
布局计算:浏览器根据生成的渲染树计算每个元素的位置和大小。
绘制生成:浏览器根据渲染树和布局计算完成后,将页面绘制出来,生成用户所看到的最终的界面。
回流、重绘
回流
回流是指重新计算网页元素的位置和尺寸,它会触发整个文档的重新布局和重新绘制,是一种较为耗费性能的操作。常见的触发回流的操作包括:
- 页面首次加载
- 添加、删除、修改DOM节点
- 页面尺寸改变
- 元素位置、尺寸、内容等属性的改变
重绘
重绘是指修改元素的背景色、字体颜色、边框的颜色等样式属性,浏览器只需要重新绘制受影响的元素即可,不会触发整个文档的重新布局,通常比回流的性能开销要小得多
如何避免回流
- 避免频繁读写DOM属性,尽量批量修改DOM属性
- 使用CSS动画代替JavaScript动画
- 避免频繁修改布局,可以将复杂元素的布局设计得更简单
- 使用离线DOM,即将元素的display属性设置为none,修改完后再重新显示元素,避免不必要的回流和重绘。
关系
回流一定会引起重绘,但重绘不一定会引起回流
循环
for in \ for of
- for in:遍历对象的可枚举属性,
包括原型链上的属性,拿的是key - for of:遍历可迭代对象,包括数组、字符串、Set、Map等,
不包括原型链上的属性,拿的是value
map \ forEach
- map:遍历数组,返回一个新数组,不会改变原数组
- forEach:遍历数组,不会返回新数组,会改变原数组
手写
防抖函数
function debounce(fn, delay) {
let timer = null
return function() {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.apply(this, arguments)
}, delay)
}
}
节流函数
function throttle(fn, delay) {
let timer = null
return function() {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, arguments)
timer = null
}, delay)
}
}
}
深拷贝
function deepClone(obj) {
if (typeof obj !== 'object' || obj === null) {
return obj
}
let result = Array.isArray(obj) ? [] : {}
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
result[key] = deepClone(obj[key])
}
}
return result
}
数组去重
function unique(arr) {
return Array.from(new Set(arr))
}
数组扁平化
function flatten(arr) {
return arr.reduce((prev, cur) => {
return prev.concat(Array.isArray(cur) ? flatten(cur) : cur)
}, [])
}
数组乱序
function shuffle(arr) {
return arr.sort(() => Math.random() - 0.5)
}
数组最大值
function max(arr) {
return Math.max(...arr)
}
数组最小值
function min(arr) {
return Math.min(...arr)
}
npm run dev经历了什么过程?
- 启动 Webpack 或者其他构建工具来编译前端代码,转换成浏览器可识别的静态资源如 HTML、CSS 和 JavaScript;
- 在开发环境下启动一个本地服务器,将编译后的前端代码部署到服务器上;
- 监听文件的变化,例如文件的修改或者新增,一旦有变化,会自动重新编译和部署最新的前端代码。
加密
常见加密插件
CryptoJS:这是一个JavaScript库,可以提供各种加密算法,包括AES、TripleDES、MD5等。它可以在浏览器和Node.js中使用。
sjcl:这是一个用于JavaScript的强密码加密库。它支持各种密码学算法,包括AES、SHA-256、HMAC等。
bcrypt.js:这是一个用于Node.js的密码哈希算法库。它使用Blowfish密码算法的变种来计算密码的哈希值。
jsencrypt:这是一个用于RSA加密的JavaScript库。它可以执行RSA加密和解密操作,可以在浏览器中使用。
MD5.js:这是一个MD5加密算法的JavaScript实现。它可以用来对密码进行哈希,但是MD5不是一个安全强度很高的算法,建议使用SHA-256等更强的哈希算法。
对称加密
对称加密算法是指加密和解密使用相同密钥的算法,常见的对称加密算法有DES、3DES、AES、Blowfish、IDEA、RC5、RC6等。对称加密算法的特点是算法公开、计算量小、加密速度快、加密效率高,适合于对大数据量进行加密,常用于对称加密算法有AES和DES算法
非对称加密
非对称加密算法是指加密和解密使用不同密钥的算法,常见的非对称加密算法有RSA、Elgamal、背包算法、Rabin、D-H、ECC等。非对称加密算法的特点是算法公开、计算量大、加密速度慢、加密效率低,适合于对小数据量进行加密,常用于非对称加密算法有RSA算法
哈希算法
哈希算法又称为散列算法,它是一种单向的加密算法,它将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希算法的特点是不可逆、不可伪造、不可篡改,常用于哈希算法有MD5、SHA-1、SHA-2、HMAC等
性能优化
减小资源请求量:合并和压缩 CSS、JavaScript 文件等、缓存静态资源等
编写高效的 JavaScript:使用事件委托、减少 DOM 操作、异步加载等
减小页面的 DOM 层级:避免嵌套过多层级的 DOM 元素,减少 DOM 操作的复杂度
CSS 选择器优化:避免使用复杂的 CSS 选择器,优化CSS,合理利用CSS预处理器等
图片优化:减小图片体积、使用 WebP 或 tuer truecolor 等格式、按需加载等
缓存机制优化:使用 HTTP 缓存、禁用缓存等
充分利用浏览器特性:使用浏览器缓存、HTTP2、WebWorker、LocalStorage等
避免阻塞渲染:使用懒加载、延迟加载等手段,避免阻塞页面渲染
两种路由模式
hash模式
通过 URL 的 hash 属性来实现路由,其原理是在 URL 后面加上一个 # 号,# 后面的内容被称作 hash。浏览器对于这种 URL 不会向服务器请求数据,只会在本地进行跳转,因此页面刷新后 hash 部分不会丢失。Hash 模式可以使用 onhashchange 事件来监听 hash 的变化,从而实现前端路由。例如,当点击导航条上某个链接时,就可以更改 URL 的 hash 部分,页面只会进行变化而不会进行真正的重新加载
history模式
利用 HTML5 的 history API 来实现路由,其原理是通过 pushState() 和 replaceState() 方法改变 URL,并在浏览器历史记录中添加或替换当前页面的状态,从而实现前端路由。与 Hash 模式不同的是,History 模式可以使 URL 更加自然和美观。例如,我们可以使用类似 /home 或 /about 的 URL 地址来访问对应的页面。但是需要注意的是,使用 History 模式时,刷新页面会从服务器端重新请求数据